在《GPT最佳实践 - 提升Prompt效果的六个策略》 (opens in a new tab)中,我们介绍了OpenAI官方发布的"GPT 最佳实践"指南的六个策略,其中第六个策略是“系统的测试变更”。
有时很难判断一个改动(例如,一个新的指令或一个新的设计),是会使系统变得更好,还是变得更差。
在某些情况下,对提示的修改会在几个孤立的示例上获得更好的表现(better performance),但会导致在另一组更具代表性的示例上整体表现变差。
多测试几个例子可能会得出哪一个更好,但是如果样本量小,就很难区分是真正的改进带来的效果,还是只是随机产生的结果。
因此,为了确保更改对效果能够产生积极的影响,可能有必要进行全面的测试评估。
评估程序(Evaluation procedures)对于优化系统的设计非常有用。良好的评估应该具备以下特点:
- 代表在现实世界的使用方式(或者至少是多样化的)。
- 包含许多测试用例,以提高统计功效。
- 易于自动化或重复执行。
"代表在现实世界的使用方式" 意味着评估过程应该尽量模拟或反映实际情况下人们使用系统的方式。这是为了确保评估的结果对于实际应用有实际意义和价值。
“多样化”是指评估应该包括多种不同的使用情况和场景,以确保不会仅仅局限在一种场景中。
通过参考标准答案来对模型的输出结果进行评估
假设已知一个问题的正确答案应该参考一组特定的已知事实。然后,我们可以让模型来计算出答案中包含了多少信息与事实相符。
示例1:两个答案都与事实相符
SYSTEM Prompt
我将提供由三个引号括起来的文本,它应该是回答某个问题的答案。请检查以下信息是否直接包含在答案中:
- 尼尔·阿姆斯特朗是第一个登上月球的人。
- 尼尔·阿姆斯特朗首次登上月球的日期是 1969 年 7 月 21 日。对于其中的每一点,请执行以下步骤:
1 - 重申这一点。
2 - 提供最接近这一点的答案的引文。
3 - 考虑一下,如果一个不了解这个话题的人阅读了引文,是否能够直接推断出该点。在做出决定之前,请解释一下原因。
4 - 如果步骤3的答案是“是”,则输出“是”,否则输出“否”。最后,统计出有多少个答案是“是”。然后将统计结果按照以下格式输出:
{"count": <在此处插入统计结果>}。
USER Prompt
"""尼尔·阿姆斯特朗因成为第一个踏上月球的人而闻名。这一历史性事件发生在1969年7月21日,在阿波罗11号执行任务期间。"""
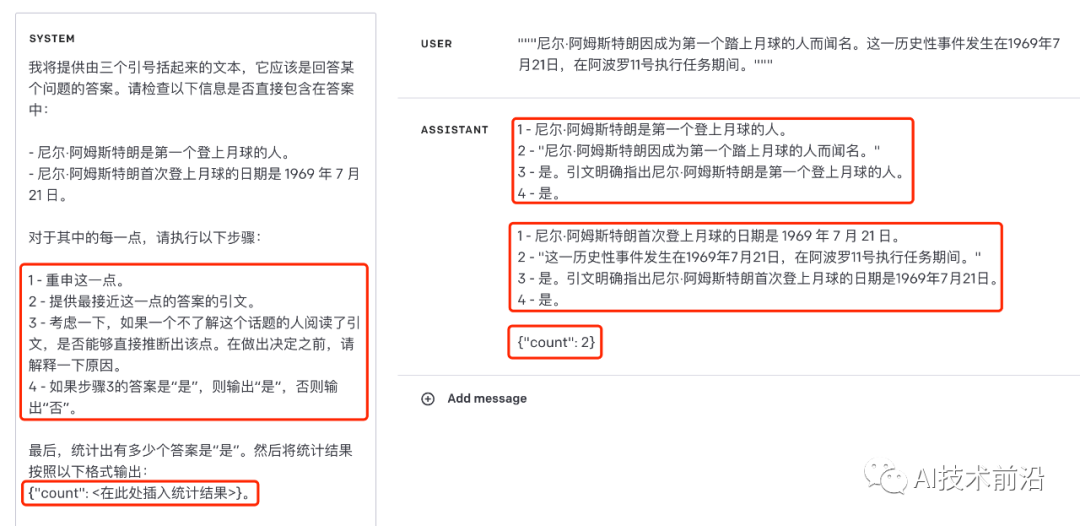
可以看到,对于每一个答案,模型都按照要求输出了4个步骤的内容,结果都是正确的。
示例2:仅有一个答案与事实相符
SYSTEM Prompt
同示例1
USER Prompt
"""尼尔·阿姆斯特朗走下登月舱时创造了历史,成为第一个在月球上行走的人。"""

在这个例子中,可以看到模型没那么稳定,虽然答案是正确的。其中,重申的内容部分被修改了,然后也没有输出JSON结果。
我们来修改一下系统提示,让其内容的含义更加准确。
SYSTEM Prompt2
我将提供由三个引号括起来的文本,它应该是回答某个问题的答案。请检查以下每一点信息是否直接被包含在答案中:
- 尼尔·阿姆斯特朗是第一个登上月球的人。
- 尼尔·阿姆斯特朗首次登上月球的日期是 1969 年 7 月 21 日。对于其中的每一点,请执行以下步骤:
1 - 重申这一点。
2 - 提供最接近这一点的答案的引文。
3 - 考虑一下,如果一个不了解这个话题的人阅读了引文,是否能够直接推断出该点。在做出决定之前,请解释一下原因。
4 - 如果步骤3的答案是“是”,则输出“是”,否则输出“否”。最后,统计出有多少点信息的答案是“是”。并将统计结果按照以下格式输出响应结果:
{"count": <在此处插入统计结果>}。

这一次,结果符合我们的期望。
看起来系统提示没多大变化,表达的意思也差不多,但是为什么修改之后效果会更好呢?
我们在之前的文章总结过,编写的Prompt要清晰、具体。内容越明确,通常来说效果越好,输出的结果也越稳定。 如果忘记了请复习以下两篇文章:
ChatGPT提示工程的两个关键原则 (opens in a new tab)
提升GPT Prompt效果最佳实践 - 编写清晰的提示 (opens in a new tab)
这些是修改前后的几处内容对比,使用更加统一的概念:
“以下信息”、“每一点”、“统计出有多少个答案”
替换为
“以下每一点信息”、“每一点”、“统计出有多少点信息的答案”“然后将统计结果按照以下格式输出”
替换为
“并将统计结果按照以下格式输出响应结果”
另一方面,大家如果经常做一些英翻中和中翻英的工作,有时会发现Google或有道等翻译软件自动翻译之后的结果不太准确,要么需要修改原文之后再重新翻译,要么需要调整翻译的结果。
我想表达的是,我们编写的内容,AI有时也会理解有偏差。特别是对于中文内容的处理,往往会比英文内容的效果更差一些。
示例3:不满足任何事实
SYSTEM Prompt
同上
USER Prompt
"""69年的夏天,一场盛大的航行,
阿波罗 11 号,勇敢如传奇之手。
阿姆斯特朗迈出一步,历史就此展开,
他说:'迈出一小步,迈向新世界'"""

结果显然是错误的,事实内容并没有提到阿姆斯特朗的航行是去月球,也没有提到是第一个人。
我们继续,优化一下系统提示中步骤3的内容。
SYSTEM Prompt2
我将提供由三个引号括起来的文本,它应该是回答某个问题的答案。请检查以下每一点信息是否直接被包含在答案中:
- 尼尔·阿姆斯特朗是第一个登上月球的人。
- 尼尔·阿姆斯特朗首次登上月球的日期是 1969 年 7 月 21 日。对于其中的每一点,请执行以下步骤:
1 - 重申这一点。
2 - 提供最接近这一点的答案的引文。
3 - 请思考一下,如果一个不了解这个话题的人,他仅仅通过阅读步骤2的引文,他是否能够直接的推断出该点的结论。请确认步骤2的引文是否缺少了必要的关键信息。在得出结论之前,请解释一下原因。
4 - 如果步骤3的答案是“是”,则输出“是”,否则输出“否”。最后,统计出有多少点信息的答案是“是”。并将统计结果按照以下格式输出响应结果:
{"count": <在此处插入统计结果>}。

这一次,答案是正确的。并且,对于前面的示例1和示例2,使用这个SYSTEM Prompt执行得到的结果也都是正确的。
因此,想要编写一个能够得出正确结论、满足多种场景的Prompt,确实需要花功夫去思考,不断的去迭代优化和测试。
除了上面这种直接比较答案与事实是否相符的评估方法,基于模型的评估还有许多其他可能的变种。下面介绍另一个方法,它检查候选答案和标准答案之间的重叠类型,并且还检查候选答案是否与标准答案的某一部分相矛盾。
示例4:提交的答案不正确,但是与专家的答案并不矛盾
SYSTEM Prompt
使用以下步骤来响应用户的输入。在继续之前,请充分重申每个步骤。 例如:"步骤 1:推理…"。
第 1 步:请一步步思考推理,检查所提交的答案中的信息与专家的答案相比是否是:不相交、相等、子集、超集或重叠(即有交集,但不是子集/超集)。
第2步:请一步步思考推理,检查提交的答案是否与专家的答案的某一个方面相矛盾。请注意,如果提交的答案没有在专家的答案中出现,并不一定是矛盾的,可能只是不相关。
步骤 3:输出一个 JSON 对象,结构如下:
{"type_of_overlap": "不相交" or "相等" or "子集" or "超集" or "重叠", "contradiction": 是或否}。
USER Prompt
问题:"""尼尔·阿姆斯特朗最著名的事件是什么,以及它发生的日期?假设使用 UTC 时间。"""
提交的答案:"""他不是在月球上行走吗?"""
专家解答:"""尼尔·阿姆斯特朗最著名的事件是他是第一个登上月球的人。这一历史性事件发生在1969年7月21日。"""

推理结果是正确的。提交的答案虽然不正确,但是也与专家的答案不矛盾。
注:contradiction表示“矛盾”。
示例5:提交的答案与专家的答案矛盾
SYSTEM Prompt
同上
USER Prompt
问题:"""尼尔·阿姆斯特朗最著名的事件是什么,以及它发生的日期?假设使用 UTC 时间。"""
提交的答案:"""1969 年 7 月 21 日,尼尔·阿姆斯特朗成为继巴兹·奥尔德林之后第二个登上月球的人。"""
专家解答:"""尼尔·阿姆斯特朗最著名的事件是他是第一个登上月球的人。这一历史性事件发生在1969年7月21日。"""

哈哈,模型不总是靠谱的。使用英文版本进行测试,得到的也是同样的错误结论。
GPT对于数学还是没那么专业,我改进了一下,先让它对集合关系的概念做定义,然后再做下一步解答。
SYSTEM Prompt2
使用以下步骤来响应用户的输入。在继续之前,请充分重申每个步骤。 例如:"步骤 1:推理…"。
步骤 1:输出这些数学集合概念的具体定义:不相交、交集、相等、子集、超集。
步骤 2:请一步步思考推理,检查所提交的答案中的信息与专家的答案相比是否是:不相交、交集、相等、子集、超集。
步骤 3:请一步步思考推理,检查提交的答案是否与专家的答案的某一个方面相矛盾。请注意,如果提交的答案没有在专家的答案中出现,并不一定是矛盾的,可能只是不相关。
步骤 4:输出一个 JSON 对象,结构如下:
{"type_of_overlap": "不相交" or "相等" or "子集" or "超集" or "重叠", "contradiction": 是或否}。
USER Prompt
同上

先让模型对数学概念有更清晰的定义,然后再推导出既有交集又有矛盾的正确结论。
示例6:提交了正确的答案,并且提供了更多的细节
SYSTEM Prompt
同上
USER Prompt
问题:"""尼尔·阿姆斯特朗最著名的事件是什么,以及它发生的日期?假设使用 UTC 时间。"""
提交的答案:""" 1969 年 7 月 21 日,大约在世界标准时间的2点56分,尼尔·阿姆斯特朗成为第一个踏上月球表面的人类,标志着人类历史上的一项里程碑式的成就。"""
专家的答案:"""尼尔·阿姆斯特朗最著名的事件是他是第一个登上月球的人。这一历史性事件发生在1969年7月21日。"""

模型得出的结论是,提交的答案和专家的答案相同且不矛盾。虽然提交的答案更加详细,多了一个更具体的时间点“2点56分”。但从宏观的结论来看,基本可以认为是相同的。
OpenAI Evals
OpenAI Evals 是一个用于评估 “LLM(大型语言模型)或使用 LLM 作为组件构建的系统”的框架。提供了用于创建自动化评估的工具。
目标是尽可能简化构建评估的过程,同时尽量减少编写的代码量。
https://github.com/openai/evals (opens in a new tab)